- 探访华为坤灵样板点:揭秘“四大神器”,助力老板们速通开店副本
近日,我们来到了位于北京科贸电子城的华为坤灵专卖店。进店之后,给我的第一感受是顺。网络连接顺畅,刷视频毫无缓冲;展厅里几块大屏同时播放高清宣传片,没有卡顿;角落的摄像头安静工作,画面清晰。店内工作人员穿梭忙碌,一切井然有序。
陶然 · 2026-07-03 13:29 - 构筑教育智能化底座,华为星河AI园区网络全面升级
2026年,AI加速迈入Agentic时代,Token的爆发式增长正重塑网络基础设施。在华为数据通信创新峰会2026上,华为面向中国区全面升级星河AI网络,打造以Token为中心的安全智联底座,携手客户与伙伴共赢Agentic AI时代新增长。而园区网络,恰恰是Token从云到端的“最后一公里”,直接决定了AI应用的实际体验与业务连续性。
陶然 · 2026-07-03 09:48 - 京彩同程,聚力向上|华为坤灵中国行2026·北京站圆满举办
盛夏京华万物并秀,智能化转型浪潮奔涌向前。以“华为坤灵,助力中小企业跃升智能化”为主题的华为坤灵中国行2026・北京站在京圆满举办。本次活动紧扣北京智能经济发展脉搏,聚焦中小企业智能化转型核心需求,300余名分销伙伴、工程商齐聚一堂,共探中小企业智能化转型升级新路径,共筑北京智能产业新生态。
陶然 · 2026-06-29 11:16 - 从“样板”到“普惠”:华为极简全闪数据中心2.0让数智化一步到位
随着AI技术应用的快速落地,各行各业正加速从传统IT基础设施向全域AI数据基础设施转型,而新型数据中心建设周期冗长、AI推理效能不足、运维难度高等痛点直接影响AI价值转化的效率。基于此背景,一场关于数据基础设施如何适配AI时代的讨论,在华为极简全闪数据中心2.0存储商业峰会上找到了现实落点。
陶然 · 2026-06-29 09:20 - 稳居全球企业存储市场榜首,戴尔科技以三大核心能力持续领跑
戴尔科技围绕当前企业最为关注的三大核心需求——可自主掌控的私有云、依托企业自有数据运行的智能引擎,以及保障整体基础架构安全的网络弹性,构建一体化存储矩阵,持续赢得客户信赖,并推动合作规模不断扩大,也因此在2026年第一季度收官之时,继续稳坐全球外部企业存储市场的头把交椅。
陶然 · 2026-06-25 11:03 - 华为助力全球运营商以网为基,以智为翼,业网算协同创新,迈向Token经营新征程
大模型和智能体技术的快速发展,为通信行业带来了前所未有的产业机遇,华为以“加速迈向智能世界”为主题,以“业网算协同创新,共赢Byte+Token双增长”为主线,亮相2026 MWC 上海,与全球运营商客户、行业伙伴、意见领袖共话联接和计算能力跃升、5G-A大上行&体验经营、AI焕新主营业务创新实践等主题,紧抓Token经营时代的新机遇。
陶然 · 2026-06-24 22:17 - 零GPU、纯CPU!当全世界都在卷显卡,中国却用“逆行”登顶世界之巅
日前,德国汉堡,ISC2026大会现场。当TOP500榜单揭晓的那一刻,一个久违的名字重回榜首——“灵晟”。2.19EFlops的持续双精度浮点性能,不仅是世界首台突破超二百亿亿次(2EFlops)门槛的超算系统,更标志着中国超算时隔九年后重返世界之巅。
陶然 · 2026-06-24 20:33 - 中科曙光亮相欧洲,展示前沿AI基础设施“中国方案”
6月23日,国际高性能计算大会ISC High Performance 2026在德国汉堡开幕。作为全球高性能计算、人工智能、量子计算领域最具影响力的盛会,本届大会聚集了欧美及亚洲各国顶尖科技企业,共同探讨AI与高性能计算基础设施的演进方向。
陶然 · 2026-06-23 22:47 - 中科曙光百核平台重估AI时代的算力价值
近日,中科曙光发布的新一代通用高性能计算平台,给出了清晰而有力的回答。该平台以国产百核级512线程通用CPU为核心,通过“算存网”全栈协同优化,整体规格首次达到国际厂商旗舰级水平,实现了国产通用计算性能的历史性突破。
陶然 · 2026-06-23 19:22 - 算力极致 AI极简 2026商业市场鲲鹏昇腾轻量化场景方案发布会圆满举办
6月17日,2026商业市场鲲鹏昇腾轻量化场景方案发布会在福州正式启幕,本次大会以“算力极致,AI极简”为主题,邀请政企客户、行业伙伴与技术专家齐聚现场,就轻量化算力落地应用、普惠AI创新实践、产业生态协同发展展开深度交流。大会同步推出一批易落地、可复用的轻量化算力场景方案,助力商业市场加快数智化转型步伐。
陶然 · 2026-06-18 17:31 - 华为极简全闪数据中心2.0存储商业峰会-暨大附一院样板点发布会成功举办
日前,以“数智普惠 一步到位”为主题的华为极简全闪数据中心2.0存储商业峰会-暨大附一院样板点发布会在暨南大学(石牌校区)成功举办。本次峰会汇聚医疗、教育、制造等行业标杆企业和生态伙伴, 通过创新产品和场景化方案发布、生态合作启动、标杆样板点揭牌、典型行业应用实践剖析和样板点参观等核心环节,探索数智普惠落地路径,加速千行百业数智化升级。
陶然 · 2026-06-16 22:08 - 国产最强通用计算平台发布:中国高精度算力底座迈入“百核时代”
中科曙光发布新一代通用高性能计算平台。该平台以国产百核级512线程通用CPU为核心,通过“算存网”全栈协同优化,整体规格首次达到国际厂商旗舰级水平,实现了国产通用计算性能的历史性突破。
陶然 · 2026-06-15 22:47 - 英特尔至强6+如何重构Agentic AI时代的算力底座
近日,在英特尔至强6+新品发布会暨数据中心创新日上,英特尔给出了一个鲜明的论断:在Agentic AI的宏大交响乐中,CPU不再是陪衬的配角,而是重回C位的指挥家,统筹着算力、存力、连接力与保障力的整体乐章。
陶然 · 2026-06-09 14:16 - 星聚鹏城,智创非凡——华为以精英圈层擘画数智人才新图景
近日,由华为主办的“星聚鹏城,智创非凡——鹏城精英茶思会暨数智人才样板点现场会”在全球数智人才发展创新基地成功举行。活动吸引了60多名已取得HCSE、HCIE证书的技术人才现场参与,共同探访全球数智人才发展创新基地样板点,见证深圳HCXE精英俱乐部正式启航,为数智人才生态建设翻开新篇章。
陶然 · 2026-06-08 15:17 - 288核,Intel 18A制程,英特尔至强6+加速Agentic AI落地
当AI步入Agentic AI时代,数据中心对算力的诉求正加速回归CPU。在英特尔至强6+新品发布会暨数据中心创新日上,英特尔给出了兼顾算力效率与应用落地的思路——依托CPU、GPU、IPU等协同运作,凭借全新至强6/6+处理器在“算力、存力、连接力、保障力”上的提升,将Agentic AI转化为触手可及的现实生产力。
陶然 · 2026-06-07 13:25 - 智能体的大考与英特尔的应答:看至强6+背后的数据中心变局
近日,英特尔在其至强6+处理器沟通会上抛出的一系列观点与产品蓝图。作为一家在数据中心CPU市场占据统治地位数十年的巨头,英特尔如何看待AI浪潮下的旧世界与新世界?其最新发布的至强6+处理器,如何应对智能体洪流?
陶然 · 2026-06-04 11:12 - 大模型进化的加速器:verl异步强化学习突破算力天花板
强化学习传统同步训练节奏固化、效率受限,难以满足高速迭代需求。如何破局?在昇腾AI开发者峰会2026上,来自verl社区的Maintainer侯正罡,给出了答案。他带来的主题演讲《verl异步强化学习的技术演进与昇腾实践》,揭示了行业突破算力瓶颈的关键路径,并向外界展示了verl社区与昇腾深度技术融合的最新成果。
陶然 · 2026-06-03 16:56 - 天生多屏:中兴AI云电脑体验日,解锁数智生活新体验
今天,中兴通讯在北京举办“天生多屏”AI云电脑体验日活动,集中展示了全栈AI云电脑产品矩阵,现场打造商务办公、生活娱乐、学习守护、康养关怀四大沉浸式体验区,全方位呈现中兴 AI 云电脑在家庭与办公场景的创新应用,为用户带来更便捷、更有趣、更安全的数智生活新体验,并携手生态伙伴加速推动AI技术从高端专属走向全民普惠。
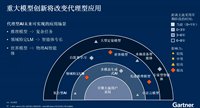
陶然 · 2026-06-03 12:48 - Agentic AI“三重门”:Gartner解读4500亿美元商机的现实与边界
在近期举行的2026 Gartner大中华区高管交流大会上,Gartner研究副总裁蔡惠芬给出了回答。她将Agentic AI的发展路径清晰地划分为“三重门”:当下可实现的、即将实现的突破,以及可能永远难以企及的领域。
陶然 · 2026-06-03 10:09 - 英特尔全栈赋能,全新至强6+、网络与AI系统共筑智能体AI基石
今日,英特尔宣布数据中心领域最新进展,推出全新英特尔至强6+处理器,发布以太网800系列新成员—英特尔以太网E835控制器及网络适配器,以及AI加速器路线图的最新进展,包括Crescent Island的更多信息。这些进展共同凸显了一个清晰的行业趋势:当AI迈向智能体时代,CPU正重返现代AI基础设施的中心。
陶然 · 2026-06-01 13:54